Set Up an Export
Exports > New Export Stream
Exports > selected Export Stream > New Export Volume
Users with the needed permissions can set up and perform an Export within the
When you choose either option the Export dialog displays, providing you with a number of options for the Export. (Some of these settings are available only when creating a new Export Stream and not when exporting aVolume of an existing Export Stream.)
If your Project is integrated with a review platform, you have two options for creating a new Export Stream: one for creating the Export Stream on the review platform, for example New Reef Review Export Stream, and New Digital Reef Export Stream for creating a standard Export Stream. Differences when exporting to a review platform are noted in the following.
Before You Export
- Become familiar with the Export process, as described in the Export Overview. This topic provides key information about Export Locations, Directory Structure, and generated files (load files, settings files, production reports, and exception files) and how to verify your exported items and generated files. It also provides a table of export exceptions and reviews how family associations are maintained across volumes.
- Make sure that there is at least one available Export Data Area. An Export Data Area (Export location) is defined as part of Organization resource management. Work with your designated administrator to ensure availability of the appropriate Export Areas, each of which is defined for one of the Organization's Connectors of a type such as NFS or CIFS. Access to the Export location is also negotiated between administrators.
If you want to use a separate Export location for
- Unless the Export is intended to capture all documents, make sure that files of interest have been tagged appropriately. You can manage Tags in the
- If you want to export email
- Use the Preview button to see what your export will look like after your criteria are calculated.
- You can selectively exclude a Volume associated with an existing Export Stream in the deduplication calculations for subsequent Export Volumeexports. To exclude the documents in a particular Volume, go to Exports in the Project Dashboard's navigation tree, expand an Export Stream to view its Volumes, then right-click the Volume and select Exclude from Export Stream. When you change the state of a Volume, a Work Basket task appears to confirm the state change; for an example, see Export Overview.
Initial Export Settings
All Exports begin with the following required fields:
Export Name
This setting determines whether you are creating a new Export Stream or adding a Volume to an existing one.
- To create a new Export Stream, enter a name for it. Export Stream names must be unique within the current Project, are case sensitive, and can include alphanumeric characters and some others such as spaces, hyphens, underscores, and apostrophes, but not the following characters: ! " # $ % & * + . / : ; < = > ? @ [ \ ] ^ { | } ~ “ ”
- To add an Export Volume to an existing Export Stream, select the Stream name from the drop-down list, which includes all Export Streams within the current Project. When exporting to an integrated review platform, only Export Streams created on the review platform are available for selection.
Export Data Area
Select an available Export Data Area from the drop-down list (alphabetical order). These export mounts are managed in Organization Settings. Ensure that you have secure access to this location to retrieve files after export. You can select a different Export Data Area when subsequently exporting a Volume of the Export Stream.
Export Fields
The fields included in an exported load file, as well as their order and names, are specified by the Export Fields template you select from the drop-down. You can use the Project's default Export Fields template, which is initially selected, another template created within the Project, or an Organization or System-level template, if available based on your permissions.
Note: Regardless of the load file output format, an additional CSV file called volume-TagReasonCodes.csv is generated at export to provide more information about how exported Tags were applied (for example, to a Work Basket Search task); for more information, see View and Learn about Document Metadata.
Export Settings
Each Project has access to one or more Export Settings templates, each of which provides a full set of Export Settings that are loaded into the Export dialog and can then be modified as needed.
- Export Settings are initially loaded from the Project's Default Export Settings template. You can also choose to start from one of the Organization or System-level templates that may be available, depending on your permissions.
-
If your system is integrated with one or more review platforms, Export Settings templates are created for a specific type of Export: to Digital Reef Only, to Reef Review, or to Relativity Server. This includes the Default Export Settings template, which must be separately created for each type of Export available. Therefore, when you create a new Export Stream, the templates available to you include only those matching the type of Export you selected.
-
When you create a new Export Volume for an existing Export Stream, the Export Settings drop-down is hidden; the initial values of the settings are inherited from the Export Stream.
-
For more information about Export Settings templates, see Manage Project Export Settings.
Documents to Export
Specify the documents to be included in the Export. You have the following options:
-
Select All Docs (ALLDOCS appears in the query box) have the Export include all documents in the view.
-
Click the Tags button to display the Select Tag dialog, on which you can select one or more Tags to have documents with those Tags included in the Export. This populates the Search Query box with the selected Tags in the Tag view syntax format, where multiple Tag views are separated by a Boolean OR and quotes appear around the Tag name, for example, tag_view::“Potentially Hot” OR tag_view::“2025 Only”). You can edit the search query if you wish.
-
Specify content or metadata to be included with a search query of your own.
Note: Do not change the name of a Tag if you have existing Exports that rely on that Tag.
Template-Based Export Settings
The remainder of the Export settings (except Generate Search Reports, below) are determined by the Export Settings template you select and are described in Manage Project Export Settings.
Generating Search Reports
Select the Generate Search Reports option at the end of the Export form to generate search reports (as CSV files included in the Export) based on queries that you provide (similar to Bulk Search). Note the following about generating these reports:
-
-
- Include Metadata — Selected by default, this option expands the search for each keyword in a query to include a set of metadata fields as well as content. You can select the Search Fields you want to have searched automatically. For a list of the default fields searched, see Using the Include Metadata Option.
- Click the Validate button to confirm the search terms are valid before you run the Export.
Search Terms
When you select Generate Search Reports, this section appears so you can specify search terms and or more complex queries. You can specify search terms on a per-volume basis. You can include not only search terms and phrases, but queries using all supported syntax, such as proximity searches and metadata field searches.
For any use of the Search Terms section, keep the Separate Email Attachments option enabled for the Export (if it is disabled, use of the Search Terms section will cause the Export to fail).
The search term queries you run as part of Export are evaluated on a per-volume basis (that is, the queries are not maintained volume to volume). When you are viewing the Export Settings for a Volume, the first five queries are shown in the Queries box. You can use the scroll bar to navigate a longer list of queries.
- After Export, your Export Data Area contains the generated reports (in CSV files). See the topic for details about these reports. For example, the
<volume>_summary_count_size.csvfile provides a summary of the document count/size and family count/size information for the files subject to the Export criteria. This file now reports the calculated deduplication counts by family and by the appropriate deduplication mode (Global, also known as Horizontal, or Custodial, also known as Vertical by Custodian). - The
searchtermsmetadata field, a special Export-only field, applies to the Generate Reports option. As long as the selected Export Fields template contains the Export fieldsearchterms, you can check thesearchtermscolumn in the generated load file to view a semicolon-separated list of the submitted search terms/queries matching a given document. For example, if a document matched submitted terms demo, newsletter, and the phrase of the, thesearchtermsfield for that document would containdemo;newsletter;(of the). - The Export Data Area also contains an overlay file in the appropriate format when there is updated data for a given volume (for example, if DuplicateCustodian field information changes for multiple Exports of an Export Stream).
Running the Export
Choose one of the following actions when they are available (based on the state of the Export). The buttons for these actions initially display an error status (for example,  ) to indicate that you must make an appropriate entry for all required fields before you can proceed. When all required fields have been addressed, the buttons change to a success status (for example,
) to indicate that you must make an appropriate entry for all required fields before you can proceed. When all required fields have been addressed, the buttons change to a success status (for example,  ).
).
Save Empty Export – Click this button (when creating a new Export Stream) to create an empty Export with the settings you have chosen for configuration. You can use the empty Export if you want to deduplicate a given search against the empty Export (for example, to get the HTML size information based on the selected email format), without actually having the first Volume of the Export in place. Once the empty Export is in place, you can view the settings you selected on the Export tab, but the Documents tab will be empty. This button will be unavailable when you are setting up a new Volume in an existing Export Stream.
Stage Export – Click this button to stage the Export, which performs the needed preliminary calculations. Error popups appear in red to indicate errors that need to be addressed. A Work Basket task is generated for the staging in the format Staging streamName at exportdatarea:projectName-streamName-volumeNameStaging export1 at exportda1:test424-export1-VOL0001
Run Export – Click this button to start the Export process. For information about verifying the exported items and generated files (load files, settings files, production reports, and exceptions), see Export Overview for more; this topic also reviews how family associations are maintained across volumes. Note the following:
- For a new Export Stream, clicking Run Export creates the named Export Stream, creates the first Volume under Exports, persisting the Volume to disk.
- For an existing Export Stream, clicking Run Export creates another Volume under the Export Stream, then stages and exports any Volume for this Export Stream that has not already exported.
- A Work Basket task is generated for an Export (not previously Staged) in the format
Exporting streamName at exportdatarea:projectName-streamName-volumeNameExporting export1 at exportda1:test424-export1-VOL0001
Cancel Click to cancel the Export operation.
The Export does not process files in which there is no discernible content, such as image files, no-content files, or stop words-only files (if stop words are ignored in an Analytic Index, for similarity and Cluster operations).
Tracking Your Export Task
After you initiate an Export you can track its progress in the associated Work Basket task. Right-click the task and select View Details to display its state, the various system components, and the configuration settings you used. Here is an example of task details for an export task in progress:
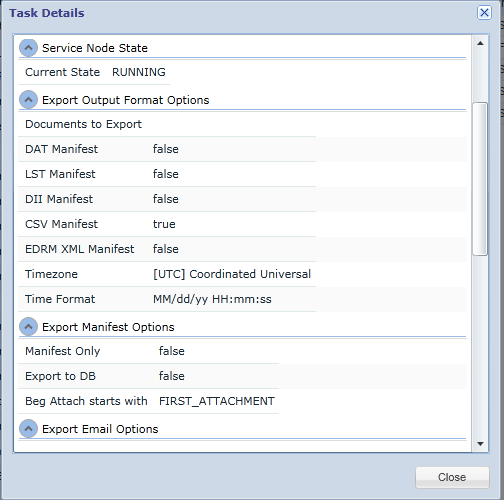
If you cancel the Export task once it is in progress, the state of the volume for the Export Stream after the cancellation depends on how far along the Export was before it was canceled. If, for example, you start a large Export and then cancel it right away, if the Export has not crossed into the Staged state, then the open volume will be deleted upon cancellation. If the Staged or Exported state has been crossed, then the volume will remain in that state. For example, if you cancel an Export at approximately 50%, the Export will be Staged and the Stream and Volume will appear populated in the tree, but no documents will be produced at the Export location. You can then right-click the Export Stream in the tree and use Export All Staged to complete the Export and produce the appropriate files.
Detecting Viruses in Exported Native Files
Upon export of native files, virus detection software installed on the system checks them for viruses. This virus detection performed at export occurs regardless of whether you have the Detect Viruses Index Setting enabled, as long as the virus detection software is installed. Any native files found to have viruses are quarantined automatically. Once the export completes, a count of the files that were quarantined is reported in the export volume report (and in the production report at the Export Area). Additional virus detection files are also available at the Export Area for the volume. For more information, see the Virus Detection section in Export Overview.
The export does not complete until the virus detection process is complete. Therefore, any export that includes native files will take longer to complete due to automatic virus detection.
This feature requires installation of the virus detection software.